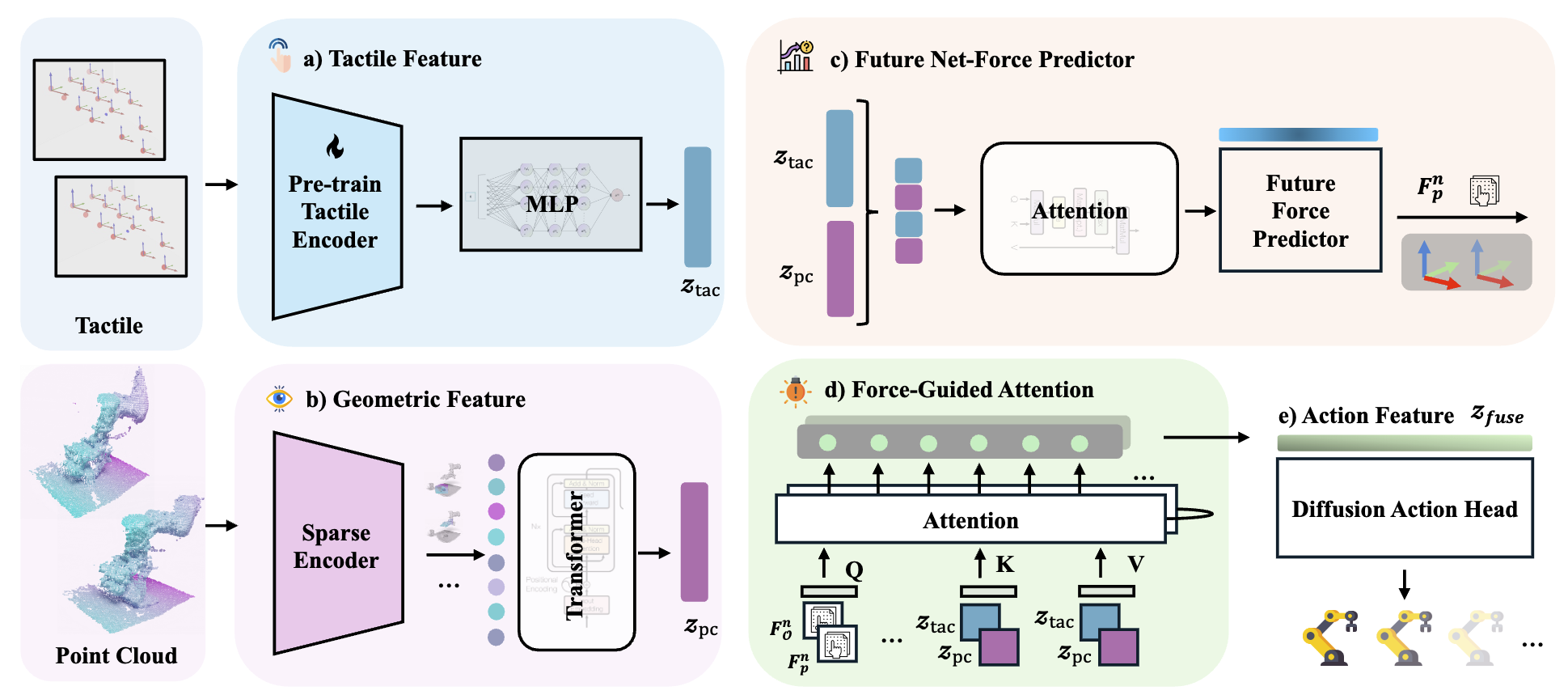
Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However,
the heterogeneous nature of these modalities makes fusion
challenging. Existing methods propose strategies to obtain
comprehensively fused features but often ignore the fact that
each modality requires different levels of attention at different
manipulation stages. To address this, we propose a force-guided
attention fusion module that adaptively adjusts the weights of
visual and tactile features without human labeling. We also
introduce a self-supervised future force prediction auxiliary
task to reinforce the tactile modality, improve data imbalance,
and encourage proper adjustment. Our method achieves an
average success rate of 93% across three fine-grained, contact-rich tasks in real-world experiments. Further analysis shows
that our policy appropriately adjusts attention to each modality
at different manipulation stages.